Guys this is insane…as soon as one changes anything to do with a virtual server SSL dovecot fails almost immediately.
I keep getting the same error over and over again…
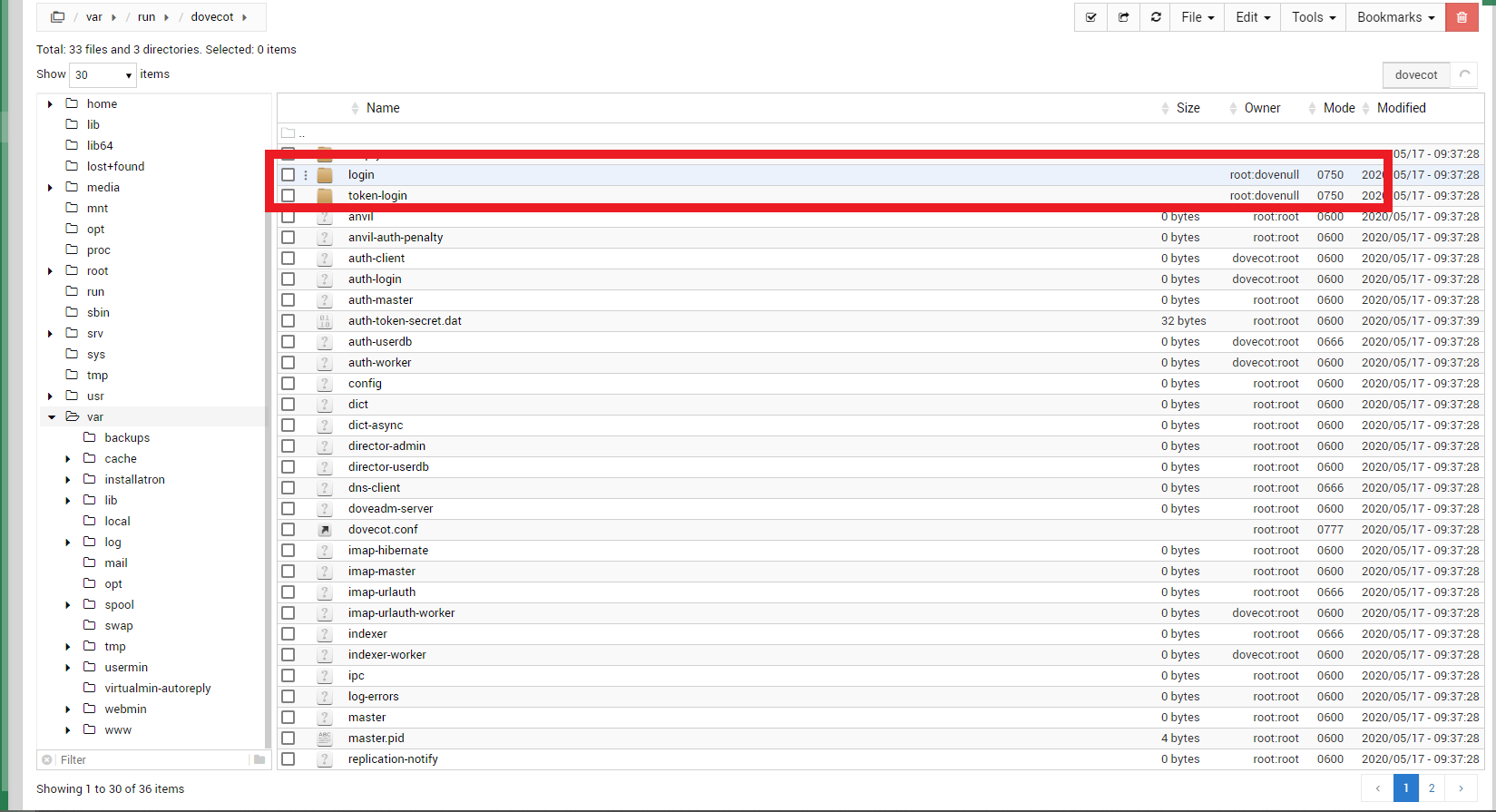
dovecot: master: Fatal: Dovecot is already running? Socket already exists: /var/run/dovecot/login/login
I am finding it almost impossible to kill the dovecot process such as dovenull and dovecot anvil. They restart in seconds after typing in systemctl kill dovecot…
the really stupid part is, webmin and virtualmin dont seem to be able to even agree with each other what in fact is the status of dovecot?
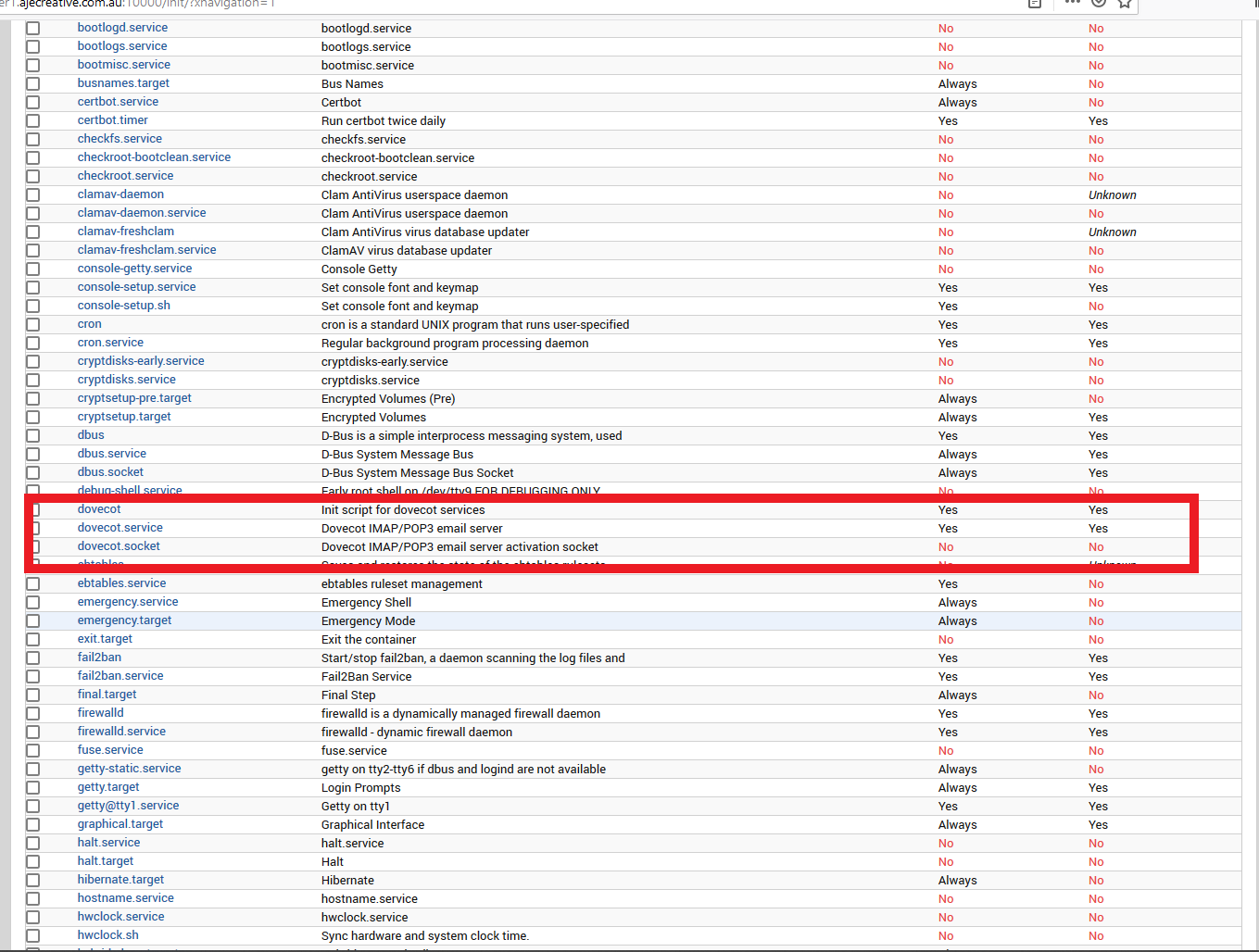
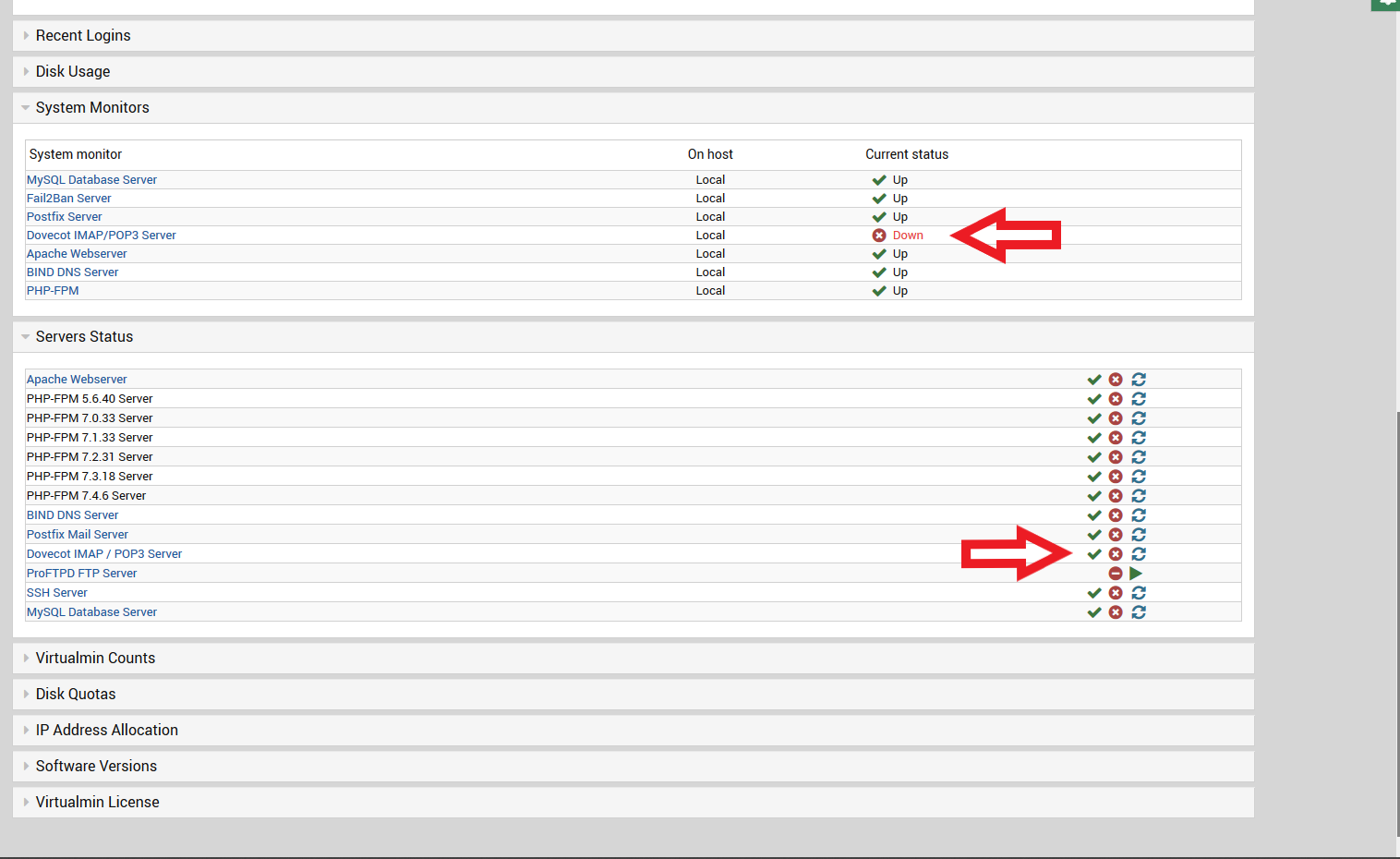
Right now Dovecot i think is actually running…
~]# systemctl status dovecot
● dovecot.service - Dovecot IMAP/POP3 email server
Loaded: loaded (/lib/systemd/system/dovecot.service; enabled; vendor preset: enabled)
Active: active (running) since Sat 2020-05-16 09:16:06 AEST; 11min ago
Docs: man:dovecot(1)
There is something wrong between virtualmin, webmin, virtual server domains, SSL, and Dovecot. Whatever it is, it is taking out the Dovecot process whenever i play with a domain in any way that involves SSL.
for example, all i did this morning was resolve a “too many redirects” issue on the website for my primary domain this morning and then dovecot stopped working again.
I went to Virtualmin>Server Configuration>website redirects…and removed the virtualmin redirect to https that was causing the error (i already have this redirect in htaccess file in public_html.
i then went to a second virtual server where the redirect from .com.au to .com domain simply refuses to work with SSL and did the same.
After doing the above and nothing more, dovecot went down within exactly the same time frame!
Something is definately not right!
also on another brand new Virtualmin GPL system (debian 10), I cannot get it to auto generate an SSL certificate for the host.tesla.com…even if i create a virtual server called clientdomain.com and use that to obtain SSL for clientdomain.com and host.tesla.com it fails. If i create a virtual server called host.tesla.com and attempt to obtain SSL from letsencrypt it also fails.
To say these issues are unrelated simply cannot be. There is something that has been done recently in webmin 6.09 update that has caused this and clearly the webmin 6.09-3 update has not resolved any of the above problems. My system has been functioning perfectly fine for almost 2 years with only minor issues, however this issue has hovered in the background for a number of months and now its turned into a full blown pandemic seemingly exacerbated by webmin updates!
I have largely gone through all of the updates during that time trouble free…but this, this has got me to the point of being forced to move across to ISPconfig (which i do not want to do…i like Virtualmin). My clients are screaming at me citing unreliability in email over the last week!
My hope is that its something i have done wrong and Im sure that i must be at fault…but if that error turns out to be running webmin updates???