Hi guys,
I have noticed that out of the blue, i am starting to see my swap file max out (the server has been running fine for more than a year with 500MB of swap, and now its doing this…
Real memory: 3.86 GiB total / 2.21 GiB free / 1.95 GiB cached Swap space: 511.99 MiB total / 42.47 MiB free
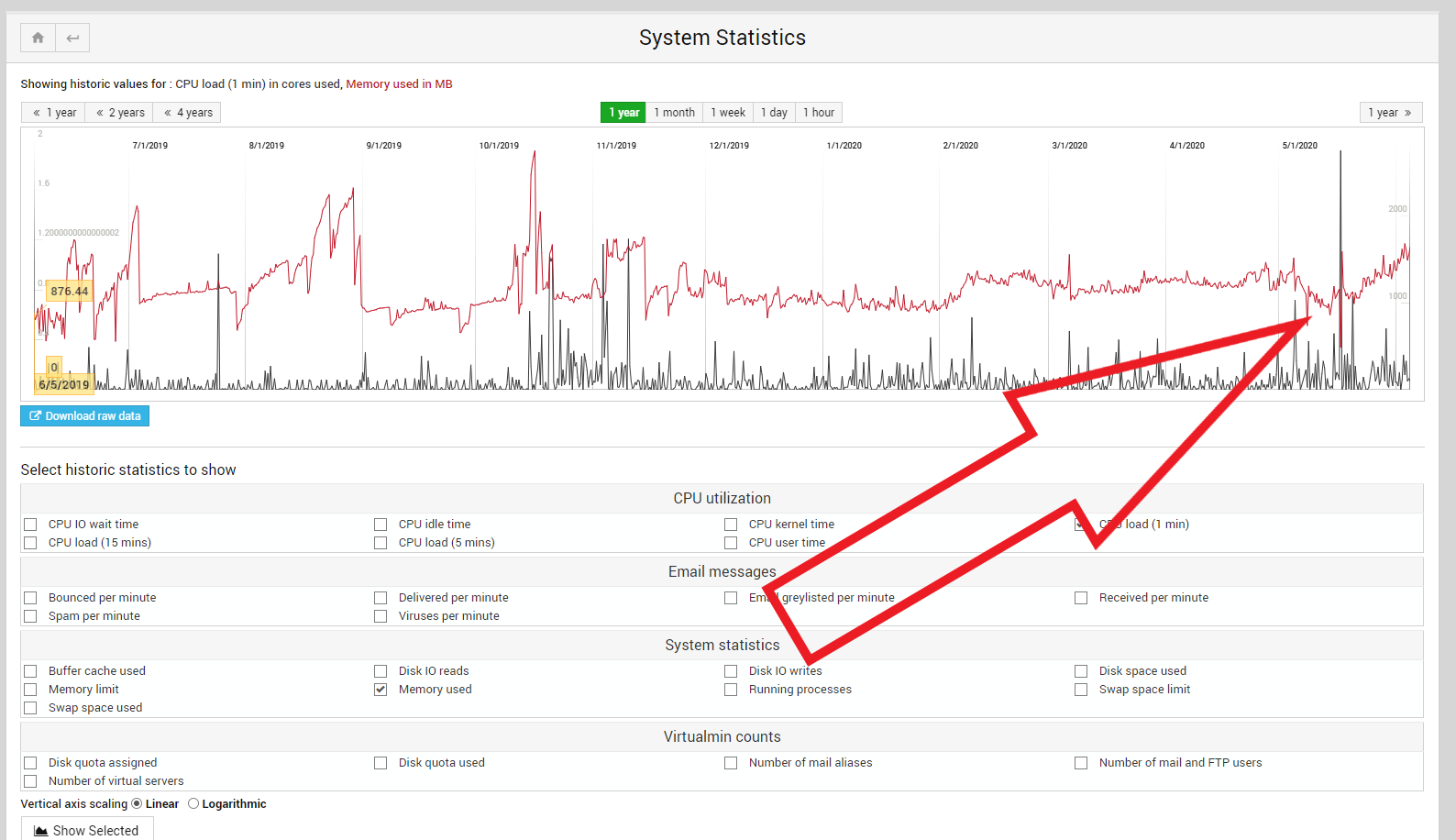
see image of ram increase over last couple of weeks…its climbing for some reason!
I had problems with dovecot and now this…any suggestions?
my swappiness value is set at the default 60
Exactly what is the best way to increase swap file size on this production system without causing any downtime? (can virtualmin do it in the gui interface or do i have to use command shell?)
I would not worry about a temporary spike in swap file usage provided I know the reason for it. Was there a backup operation underway when this happened or were you installing / upgrading software at that particular point in time or was the system carrying out a scheduled operation?
Be mindful that we will see some anomalies in usage patterns as our users emerge from COVID-19 lockdown.
Key to understanding the spike is the process which caused memory usage to increase such that the system had to use swap space. I approve of your decision to use a relatively small amount of swap space: 512 MB on a 4 GB system . Performant systems don’t need much swap space.
waht concerns me though is that for the last month dovecot has been running stupidly…you might recall my other thread about dovecot issues.
the system monitor was believing that dovecot was down and attempting to start up a second instance of it by mistake. that was then throwing a failed state error.
i have reset the swap file anyway, i dont want it to max out whilst i am asleep during the night and cannot check on what the consequence of that may be for my system and client accounts.
I am wondering if the two (ie dovecot failing and now this swapfile maxing out) are connected?
I have been observing the interaction between yourself and Joe on the other thread about Dovecot with great interest. In that and even here, you have expressed your discomfort at the idea of being unaware of one of the services on your system failing. I hate that this is diminishing for you the joy and satisfaction of systems administration.
Since we appear to have expanded the scope of our discussion to the broader aspects of offering high uptime, I would like to suggest that you avoid single points of failure and use tools to monitor your systems so that you can be alerted via email / SMS / push notifications in the event of a service failing or an anomaly in usage patterns. You have already provisioned a backup mail server, I recall reading somewhere, so you have avoided a single point of failure for mail. You should likewise arrange redundancy for other critical services. Additionally you should setup or subscribe to a monitoring and alerting system which operates independently of the systems that it monitors i.e. if Virtualmin’s Postfix fails, Virtualmin’s monitoring system will be unable to send you an email alerting you about it; an external alerting system is therefore required.
In summary, systems which work perfectly for weeks and months on end will suddenly fail; we must build redundancy and have an effective monitoring and alerting system in place so that we can be confident of being able to offer high uptimes and, at the same time, have fun administering systems.
yes that is a good idea.
what are your suggestions for starting out in notification options?
On the wordpress websites, its relatively easy because i can and do use Jetpack, however that is obviously further down the chain than i think is appropriate for server administration. One needs to monitor higher up.
Hi !
I’ve got suddenly this problem last year.
It took me months to understand why a server running for years and years suddenly went out of control with that swap full problem.
The most obvious symptom was with the mail. I suspected dovecot, but it wasn’t.
My problem was : it was a VPS with control over the swap filed blocked by “superuser”. The provider one year before closing the service, reduced it from 2G to 500M.
The full swap problem was (probably) caused by clamav witch needs a lot of ram as it need to store virus definitions live on RAM.
The behavior is : when filled up, it blocks, especialy mail server.
If you can increase it, do it. You’ll see many opinions about swap size. The middle opinion is : 2G .
On my main (real) server (16G RAM) swap (set at 50) keeps 0%.
On a VPS with only 2G and 2G swap , 25% ram used and 30% swap used. Works like a charm. I guess the system sends rarely used ClamAV memory to swap, so allow a lot of swap.
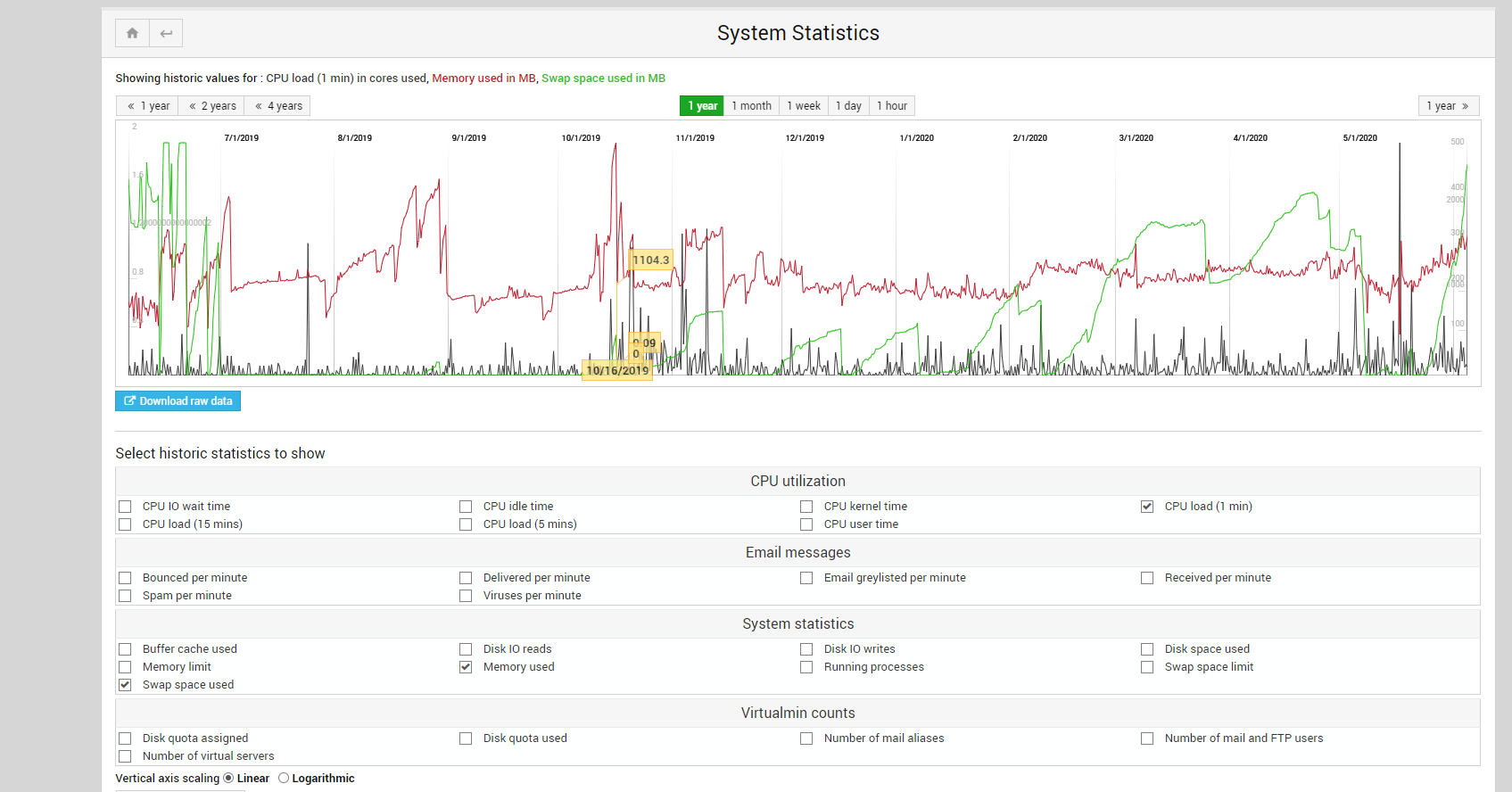
 . Performant systems don’t need much swap space.
. Performant systems don’t need much swap space.