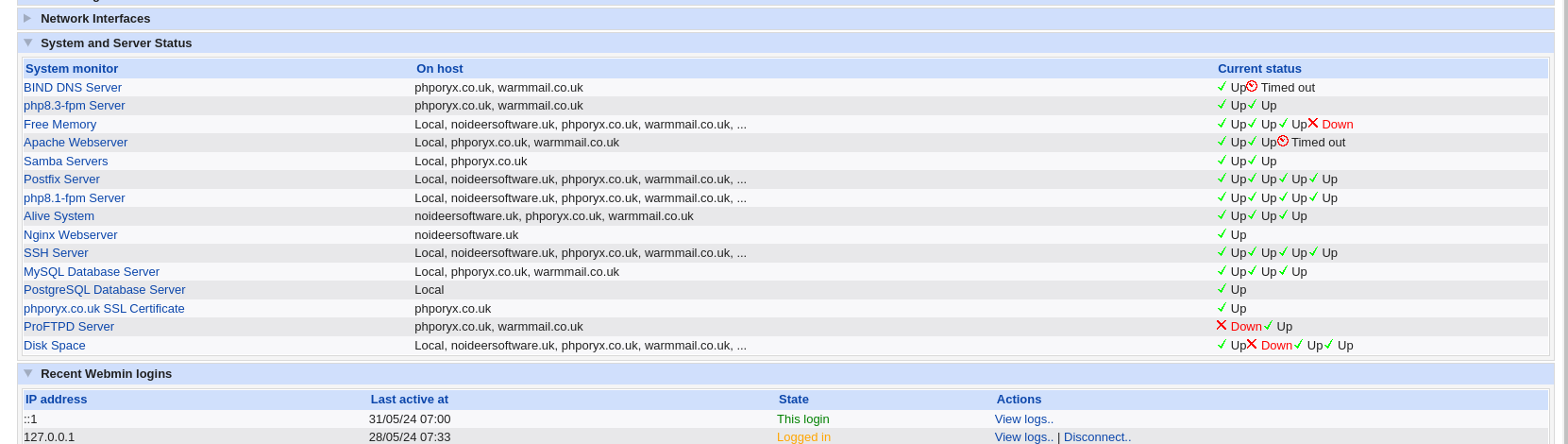
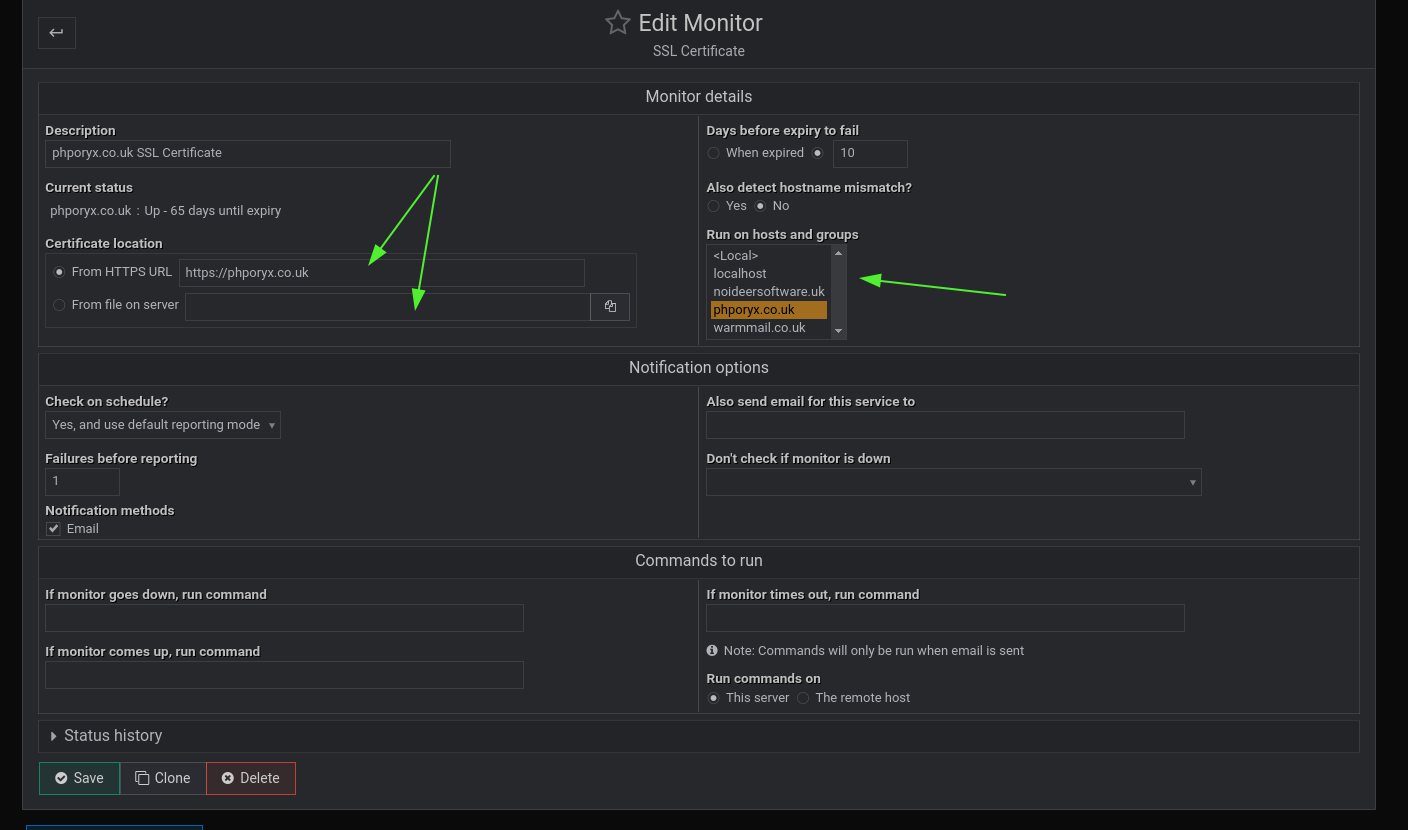
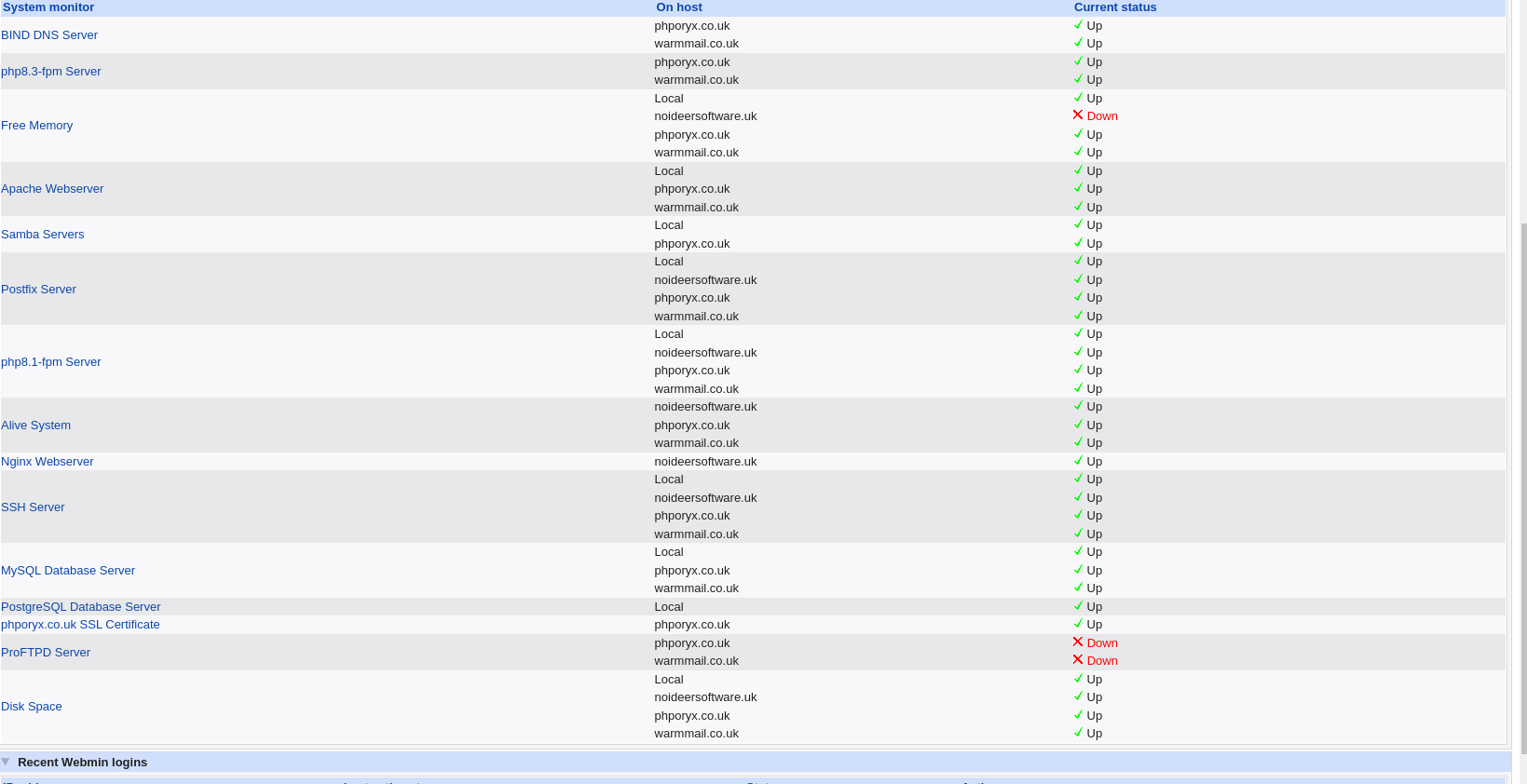
is it possible to sort the cyan arrowed column on monitor name, they appeared sorted in the module but not on the dashboard.
The 2 green arrowed columns are difficult to read as you have to count the hosts across to work out which one has failed. Could you just make these columns just 1 column and use a format like <hostname> - <status> for as many hosts you are monitoring and also turning the hostname text into a link (the same as the link in webmin->webmin->Webmin Servers Index->registered server) meaning click on the arrowed link
so you goto the failed server in one click rather than opening a new tab etc, to get there. I understand that this may not be suitable for webmin systems that don’t manage remote webmin installations, but for server empire owners such as @Stegan this may make their life a bit easier but may be not
another small point the Monitor history shows values ( free memory & disk space) on a host that is in failure could the value be added after the warning icon, as it, in some cases, be a false negative and the value will either prove or disprove that
If you select more than one host here you can not enter the relevant information for each individual host, so if you select multiple hosts system monitor only queries the url or file contained in the 2 arrowed fields
I am not the person to look at very bright screens (I have an eye condition) so I will always favor a dark screen but on framed there does not appear to much contrast between the tick and the background.
displaying each host on a seperate line does increase the screen real estate though I had to remove the top charts (authentic) to make the screen display a bit smaller, but I do have the charts (if I need them) in the right hand slider
mind on one of the remote hosts I now get this error
Port number above 0xFFFF, will be truncated to 49163 for Socket::pack_sockaddr_in at /usr/share/webmin/fastrpc.cgi line 352.
Port number above 0xFFFF, will be truncated to 49162 for Socket::pack_sockaddr_in at /usr/share/webmin/fastrpc.cgi line 352
repeated so many times it consumed 3.8gb of disk space in 4 hours, so not 100% related to this thread, but is there a fix for that ?
I don’t know what is causing this, although I think it’s a symptom of too many local ports being opened! I will fix that warning message in the next release though.
It turned out, for whatever reason, that the errors came from each server checking itself & the others in the servers index. Changing the poll times on each server to something different from the default 5 minutes solved it, so server A 5 mins, Server B 6 mins Server C 7 mins etc. etc. I’m guessing it flooded as everyone was hitting everyone else at around the same time