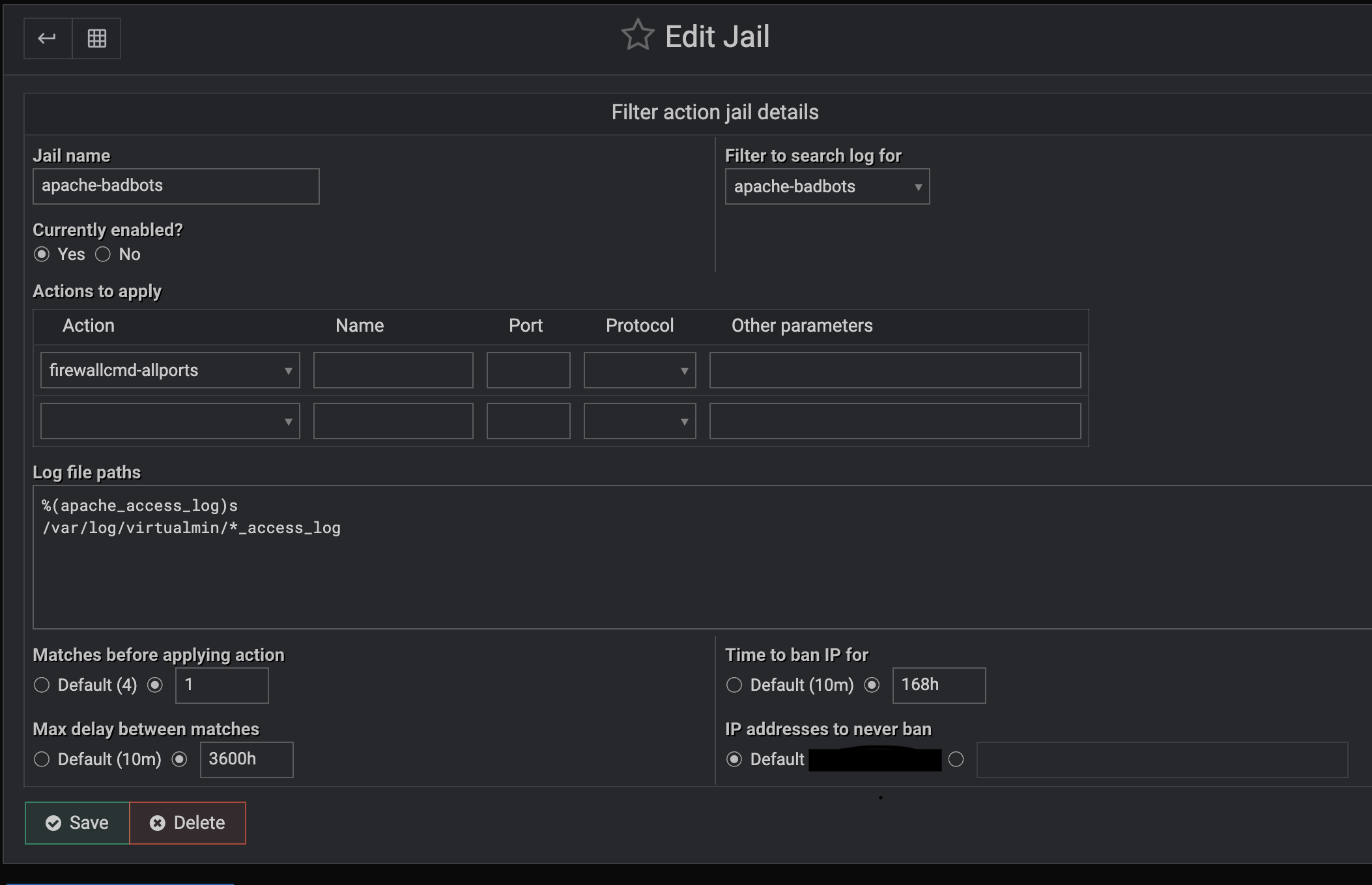
My website is getting hammered by ClaudeBot and I’ve been trying to defend myself with fail2ban but its rather failing2ban right now. This is the configuration I have for bad bots
Now when I grab an IP address from the access logs and search the fail2ban logs, I see something like this:
2024-12-04 13:11:01,449 fail2ban.filter [821]: INFO [apache-badbots] Found 3.137.178.122 - 2024-12-04 13:11:01
2024-12-04 13:11:01,449 fail2ban.filter [821]: INFO [apache-badbots] Found 3.137.178.122 - 2024-12-04 13:11:01
2024-12-04 13:11:01,664 fail2ban.actions [821]: NOTICE [apache-badbots] Ban 3.137.178.122
2024-12-04 13:11:02,160 fail2ban.filter [821]: INFO [apache-badbots] Found 3.137.178.122 - 2024-12-04 13:11:02
2024-12-04 13:11:02,177 fail2ban.filter [821]: INFO [apache-badbots] Found 3.137.178.122 - 2024-12-04 13:11:02
I notice 2 issues here. First, the IP address was found twice before getting banned. I believe I configured badbots to trigger on the 1st match. Secondly, there are more “Found” logs after the ban. Should this happen? Does that mean the IP is still able to access the server or am I reading the logs wrong?
I can confirm in the Jails list of banned IPs this one is present in the badbots list.
PS - Its not an IP specific issue, I’m just using this as an example. The same pattern is observed for all IPs. Please help.
But, yeah, it does seem to be failing to work. There have been several discussions about fail2ban not actually updating the firewall in a way that works. I don’t remember if that was about Ubuntu 20.04 or some other distro…but, there was a problem in the package, maybe, where it wasn’t doing the right thing for ipset-based firewall rules, or something. Vague recollections, here, search the forum, I know it’s been discussed and resolved several times.
Boot order is an issue with fail2ban and firewalld. Restart firewalld and then fail2ban to update it. I had to change a setting in firewalld to keep the fail2ban if it restarted for some reason.
And it seems to have been reset. I’ll have to figure out where to change it so that doesn’t happen again. Sigh…
# FlushAllOnReload
# Flush all runtime rules on a reload. In previous releases some runtime
# configuration was retained during a reload, namely; interface to zone
# assignment, and direct rules. This was confusing to users. To get the old
# behavior set this to "no".
# Default: yes
FlushAllOnReload=yes
All the major AI bots respect robots.txt, but there certainly are smaller companies that are shady and will steal content without regard for robots.txt. (They’re all stealing content, but at least some of them will stop stealing if you ask nicely. Though just about every website has been ingested into most of the copyright laundering machines by now.)
I’m wondering how to do that myself in Virtualmin. F2B does support it but not sure how to do that in Virtualmin since the command has a placeholder for the ip <ip>. Do share if you know how to do it.